
GPT-4 has captivated mainstream attention in recent months, with applications like ChatGPT showcasing its extensive capabilities and setting the stage for a generational shift in technology. The GPT-4 model can be accessed programmatically using an API, enabling the creation of diverse applications with rich, contextually relevant data. This blog post aims to demystify the process of building apps that leverage GPT-4. We will explore this by walking through the development of a Japanese Kanji Flashcard App, employing GPT-4 to build the app and supply it with valuable data.
As we move forward, we'll explore the challenges of learning Japanese Kanji, utilize ChatGPT to build the front-end, employ GPT-4's data generation logic to dynamically fetch and format Kanji data, and ultimately, bring it all together into a unified app using Python and Flask.
You can view the final result in the animated GIF below, and find the source code for this project in this GitHub repository.
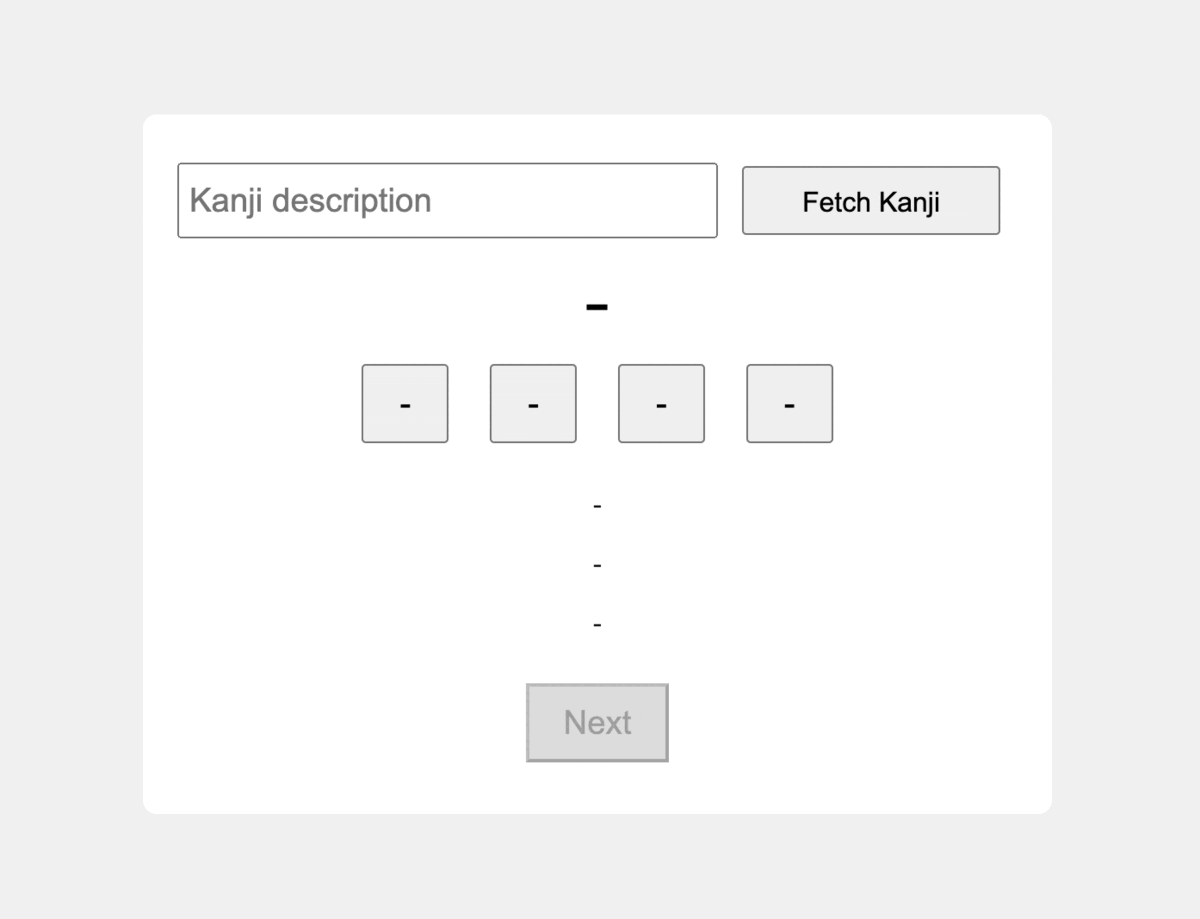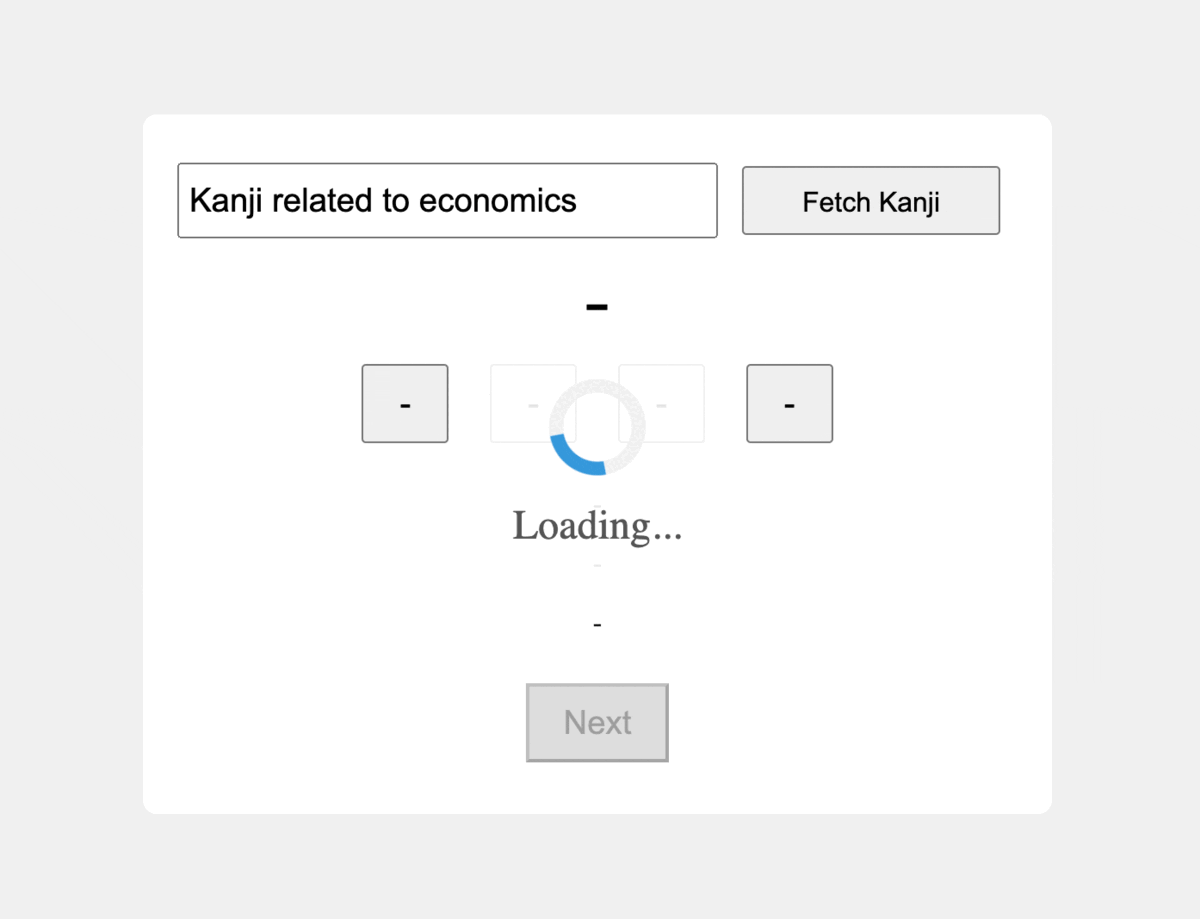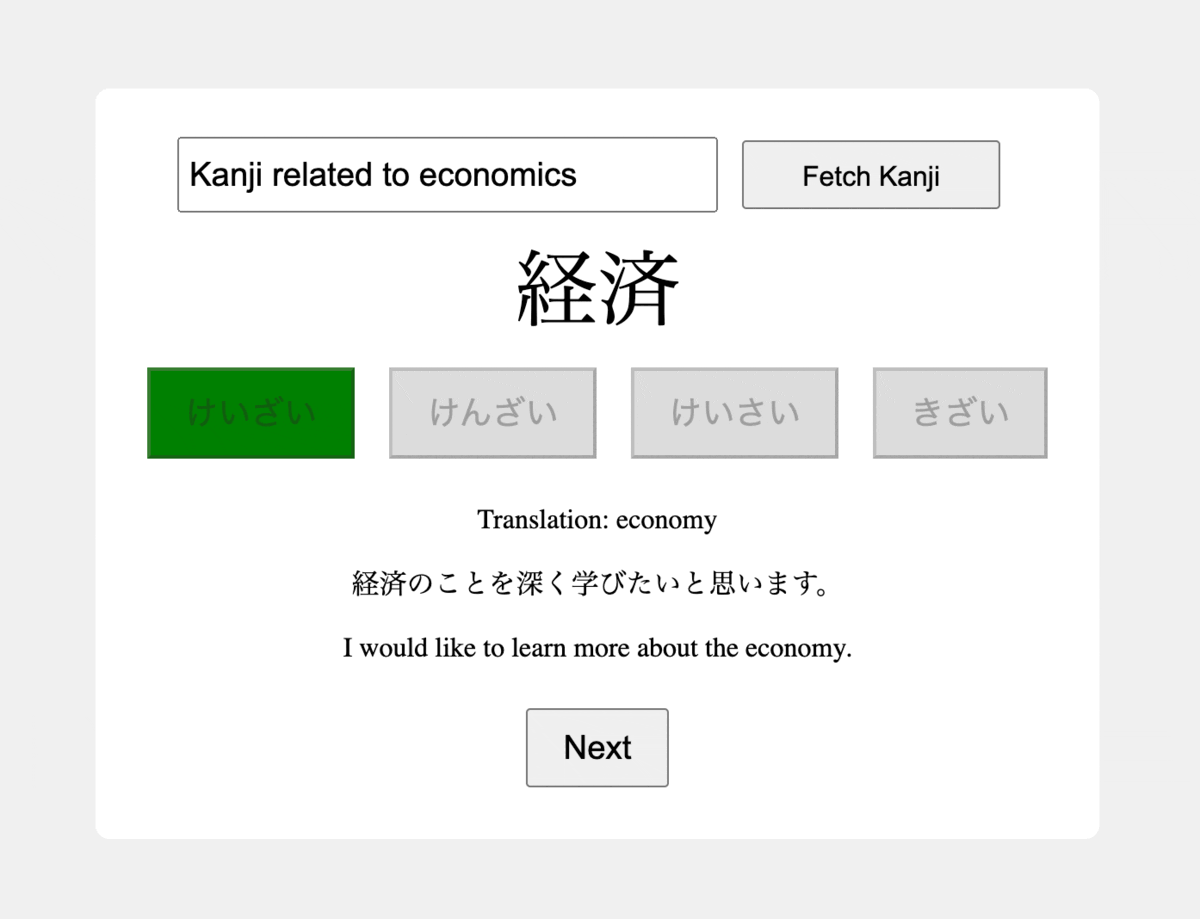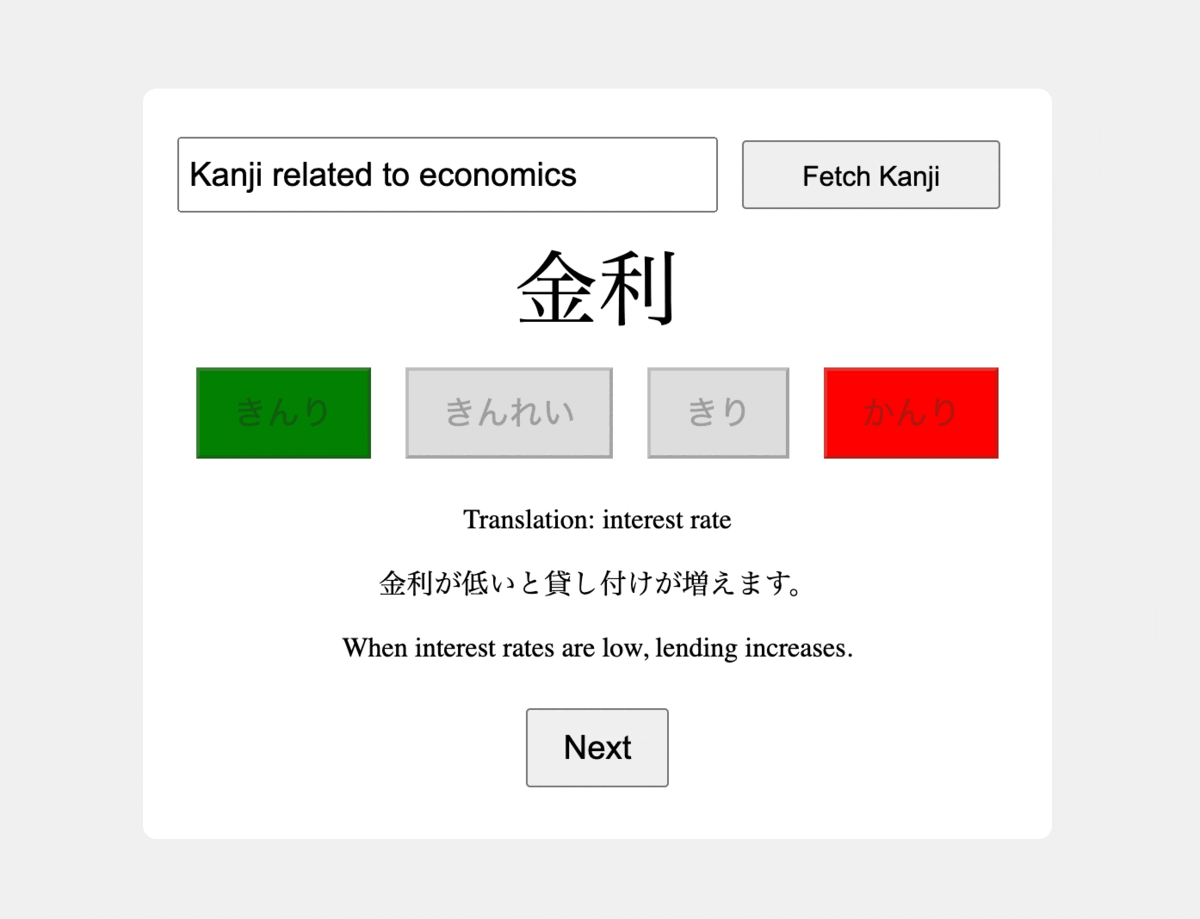
1. Defining the Use Case
When students begin the journey of learning Japanese, they are met with a fascinating yet complex writing system composed of three scripts: Hiragana, Katakana, and Kanji. Take, for example, the phrase "東京タワーは高いです。" (Tōkyō Tawā wa takai desu), where "東京" (Tokyo) is in Kanji, "タワー" (Tower) is in Katakana, and the connecting grammar is in Hiragana. This phrase translates to "Tokyo Tower is tall." The combination of scripts, each serving a different function —Kanji for most nouns, verbs, and adjectives, Katakana for foreign and borrowed words, and Hiragana mainly for grammatical functions— is a distinctive feature of the Japanese written language.

Hiragana and Katakana, each with 46 basic characters, are phonetic scripts, whereas Kanji, adapted from Chinese characters, bear meanings and often have multiple readings. While there are tens of thousands of Kanji characters, general literacy in Japan revolves around a set of 2,136 characters, as defined by the Joyo Kanji list.
In the table below, you can see the list of Hiragana and Katakana characters and their corresponding readings. In each box, the Hiragana character is displayed on the left, and the Katakana character on the right.

Below you can see a small sample of Kanji characters.

Addressing the challenges faced by students of Japanese Kanji, the objective is to build a Kanji Flashcard App empowered by GPT-4’s capabilities to facilitate the learning journey. This app serves as a dynamic learning companion, enabling users to specify, in natural language, the particular Kanji they wish to explore. Harnessing the power of GPT-4, the app automatically curates a list of Kanji that aligns with the users' articulated needs and further assesses their abilities by offering multiple-choice readings of the words, ensuring an engaged and effective study experience.
2. Building the front-end
Our next step is to build the front-end for our Kanji Flashcard App, which we'll integrate with the GPT-4 API in section 4. To achieve this, we'll employ ChatGPT, utilizing the GPT-4 model, and apply the following prompt to generate our front-end's HTML/CSS/JS code.
Develop a flashcard app to facilitate the study of Japanese Kanji, utilizing HTML, JavaScript, and CSS for implementation. The app should have the following functionalities:
1- Upon launching, the app presents a Japanese word in Kanji, accompanied by four buttons containing Hiragana readings: one correct and three incorrect options.
2- When the user selects an answer, the corresponding button should be highlighted in green if it's correct, and in red if it's wrong, while also highlighting the correct button in green.
3- Once an answer is selected, the app should display the English translation of the word, present the word within the context of a Japanese sentence, and also provide its English translation.
4- Include a button to transition to the subsequent word.
5- Populate the app with 10 different words in Kanji to test the app. The incorrect options should also be realistic and relevant to the correct answer.
6- Make sure the app is centered on the screen and use simple styling.
The gif below shows the front-end, entirely crafted with ChatGPT. This impressive result demonstrates the ability of GPT-4 to streamline the development process and make it more accessible, even for those with limited front-end experience.
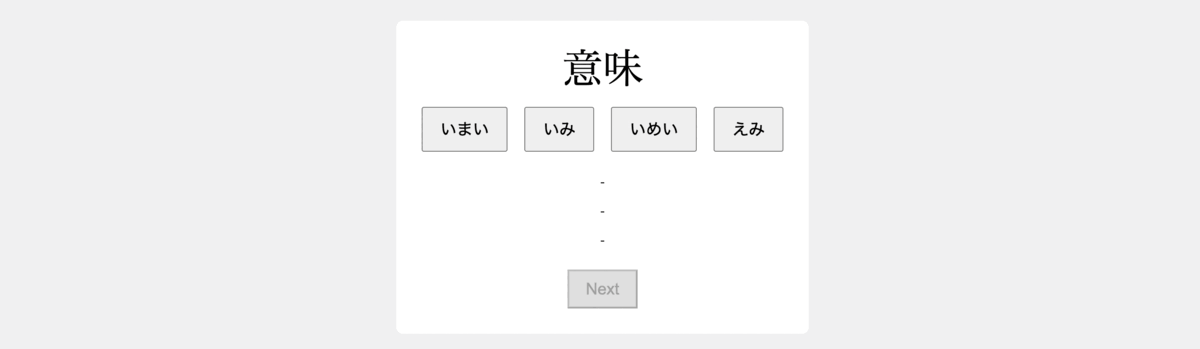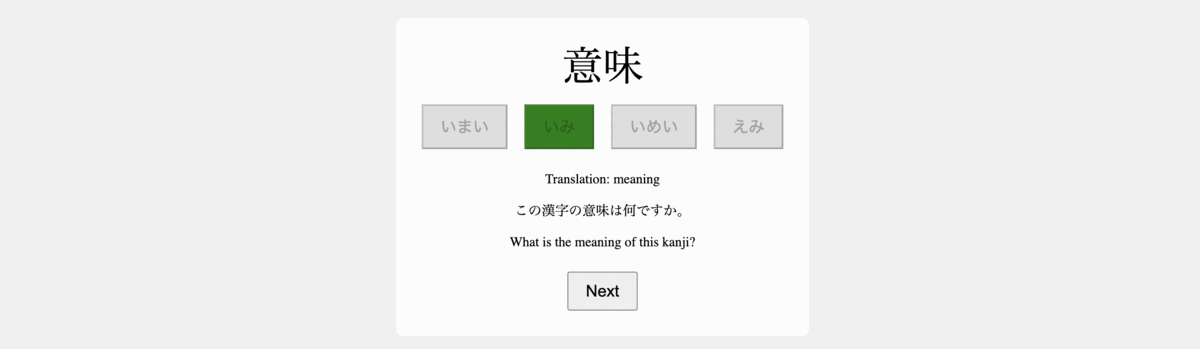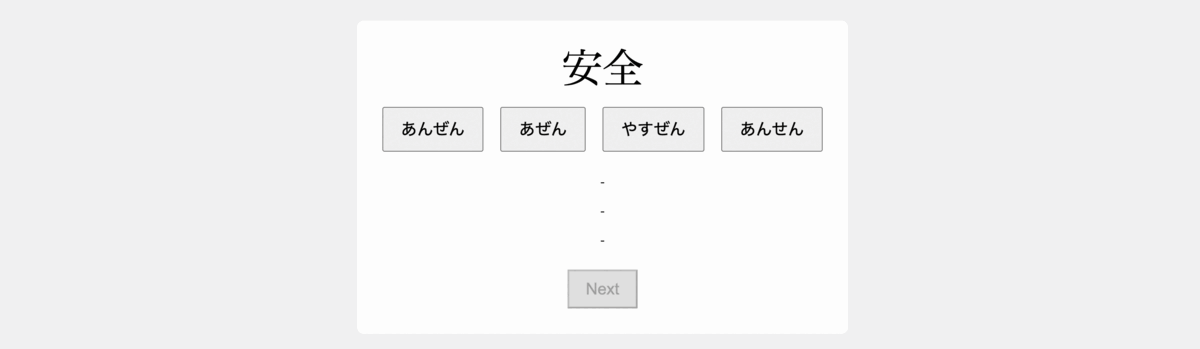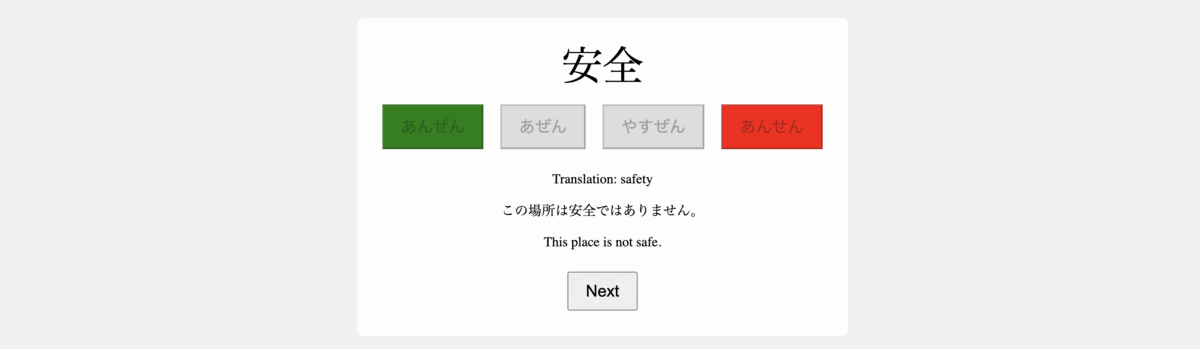
3. Building the Data Generation Logic
In this section, we will construct the backend logic for our Japanese Kanji Study Flashcard App using GPT-4. This backend will be responsible for fetching and formatting the Kanji data. To achieve this, we'll utilize Python in combination with LangChain. LangChain is a specialized framework designed for creating applications driven by large language models, including those from OpenAI. It offers various abstractions for interfacing with the API, crafting prompts, and structuring the returned outputs.
We'll begin by importing the necessary libraries. From Langchain, we specifically need ChatOpenAI to communicate with GPT-4 and ChatPromptTemplate to create a prompt template for our use case.
import os
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
Following that, we specify the model ("gpt-4-0613") we intend to deploy. It's crucial to ensure our API key is correctly configured. After doing so, we establish a connection with GPT-4. For a comprehensive list of available OpenAI APIs, visit here. For details on the API and instructions on acquiring an API key, you can refer to this link.
llm_model = "gpt-4-0613"
OPENAI_API_KEY = openai_API_key
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
chat = ChatOpenAI(temperature=1, model=llm_model)
Next, we construct a Langchain template specifically designed for our requirements. Think of Langchain templates as predefined forms. These forms allow us to structure a prompt for GPT-4, incorporating specific variables we wish to set before sending the request. For our purpose, the template will hold the prompt designed to retrieve and format Kanji words along with additional data. Our variable, in this instance, denoted by {description}, will represent the specific description of the Kanji we're interested in.
string_template = """Give 2 words written in Kanji that are: ```{description}```, \
accompanied with its correct Hiragana reading and three incorrect Hiragana readings \
that are realistic and relevant to the correct answer. \
Also give me the English translation of the word, and present the word within the context \
of a Japanese sentence, and also provide its English translation.
Format the output as JSON with the data represented as an array of dictionaries with the following keys:
"word": str // Japanese word written in Kanji
"correct": str // Correct reading of the Kanji word in Hiragana
"incorrect": List[str] //Incorrect readings of the Kanji phrase
"english": str // English translation of the Kanji word
"sentenceJP": str // Example sentence in Japanese using the Kanji word
"sentenceEN": str // English translation of the example sentence
"""
prompt_template = ChatPromptTemplate.from_template(string_template)
With our template in hand, we can retrieve the Kanji words from GPT-4, for instance, asking for Kanji related to Economics.
description_example = "related to Economics"
kanji_request = prompt_template.format_messages(description=description_example)
kanji_response = chat(kanji_request)
print(kanji_response.content)
In this case, we received a well-structured JSON. However, if the response doesn't match our desired format, Langchain offers a variety of output parsers to help shape the output accordingly.
[
{
"word": "経済",
"correct": "けいざい",
"incorrect": ["けいせい", "えいざい", "けんざい"],
"english": "economics",
"sentenceJP": "経済の状況を理解するためのデータが必要です。",
"sentenceEN": "We need data to understand the economic situation."
},
{
"word": "財政",
"correct": "ざいせい",
"incorrect": ["さいせい", "ざいぜい", "ざいしょう"],
"english": "finance",
"sentenceJP": "政府は財政問題に対応するための新たな策を立てます。",
"sentenceEN": "The government will devise new measures to deal with financial problems."
}
]
4. Putting it Together
With our data generation ready, we now need to connect it to our front-end. We'll use Flask for this. Flask will turn our data generation logic into an API and also manage our front-end. The code is short, under 50 lines, with two main routes: the root route (/) to serve the front-end and the /get_words route to invoke our data generation logic based on front-end input and return the Kanji data in JSON format.
import os
import json
from config import *
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from flask import Flask, render_template, request, jsonify
app = Flask(__name__)
llm_model = "gpt-4-0613"
OPENAI_API_KEY = openai_API_key
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
chat = ChatOpenAI(temperature=1, model=llm_model)
string_template = """Give 2 words written in Kanji that are: ```{description}```, \
accompanied with its correct Hiragana reading and three incorrect Hiragana readings \
that are realistic and relevant to the correct answer. \
Also give me the English translation of the word, and present the word within the context \
of a Japanese sentence, and also provide its English translation.
Format the output as JSON with the data represented as an array of dictionaries with the following keys:
"word": str // Japanese word written in Kanji
"correct": str // Correct reading of the Kanji word in Hiragana
"incorrect": List[str] //Incorrect readings of the Kanji phrase
"english": str // English translation of the Kanji word
"sentenceJP": str // Example sentence in Japanese using the Kanji word
"sentenceEN": str // English translation of the example sentence
"""
prompt_template = ChatPromptTemplate.from_template(string_template)
@app.route('/')
def home():
return render_template('index.html')
@app.route('/get_words', methods=['POST'])
def get_word():
description = request.json.get('description', '')
words_request = prompt_template.format_messages(description=description)
words_response = chat(words_request)
return jsonify(json.loads(words_response.content))
if __name__ == "__main__":
app.run(port=5000)
On the front-end side, we introduce minor changes: an input field and a button enabling users to specify the type of Kanji they wish to explore, accompanied by a loading spinner indicating the data retrieval process.
To start the app, run the command python app.py from a terminal, and then navigate to http://127.0.0.1:5000 in your preferred browser.
5. Ideas for Optimization and Scaling our App
The app we've constructed is fully functional and works well for studying Kanji. Nonetheless, there are certain cost and performance considerations that we need to pay attention to.
Cost
OpenAI's pricing model charges based on tokens consumed during API calls. As of this writing:
- GPT-4 (8K context) is priced at $0.03 per 1K tokens for inputs and $0.06 per 1K tokens for outputs.
- GPT-3.5 Turbo (4K context) is priced at $0.0015 per 1K tokens for inputs and $0.002 per 1K tokens for outputs.
- You can find OpenAI pricing details here.
For our specific scenario, a prompt that fetches and formats 5 Kanji words via GPT-4 utilizes approximately 188 input tokens and 176 output tokens, which translates to a total expense of $0.0162.
To get the number of tokens consumed and cost in USD, you can execute the following code:
from langchain.callbacks import get_openai_callback
with get_openai_callback() as cb:
description_example = "related to Economics"
kanji_request = prompt_template.format_messages(description=description_example)
kanji_response = chat(kanji_request)
print(cb)
While this cost structure might seem acceptable for a few API calls, scaling the app to cater to a larger user base would escalate these expenses.
Execution Time
It takes about 17.2 seconds to fetch and format 5 Kanji words using GPT-4. Such latency can negatively impact user experience.
To optimize and scale our app efficiently, we could consider an approach that combines our data sources with GPT-4 API calls and simplifies the prompts and output formats. For instance, we could obtain all characters from the Joyo Kanji list and use GPT-4 for one-time translations and sentence examples. Then, the prompts can be simplified by asking GPT-4 to fetch Kanji words related to a specific topic without needing translations or sentence examples. Afterward, we can match these Kanji with our pre-generated sentences. This method could potentially speed up the execution time and reduce token usage.
Conclusion
In conclusion, GPT-4 is changing the game in app development, especially when it comes to handling data. Our Japanese Flashcard App shows just how handy GPT-4 can be. Instead of manually gathering data, developers can use GPT-4 to quickly get the info they need. This not only speeds up the building process but ensures the app is filled with useful content. With tools like GPT-4, creating data-rich apps has never been easier or more efficient.
Go Top
comments powered by Disqus