
In a few years, massive open online courses, most commonly referred to as MOOCs, have exploded in popularity. These online courses provide high quality content taught by the best professors in their respective fields. With more that 20 million students, Coursera is one of the leaders of the MOOC movement. Coursera provides a platform that connects leading universities with students worldwide. I took my first Coursera course back in 2012, and since then I try to take one course a month.
In 2015, Coursera has around 1000 courses offered by 100+ universities in more than 10 languages. With this huge number of courses, it became difficult to decide on what course to take.
In this tutorial, I will combine coursera data together with social media data to assess the popularity of courses. To to this, I will use the Coursera API to retrieve the course catalogue, I will use the sharecount.com API to get social media metrics for each course, and I will use python's pandas library to query and order the courses by popularity.
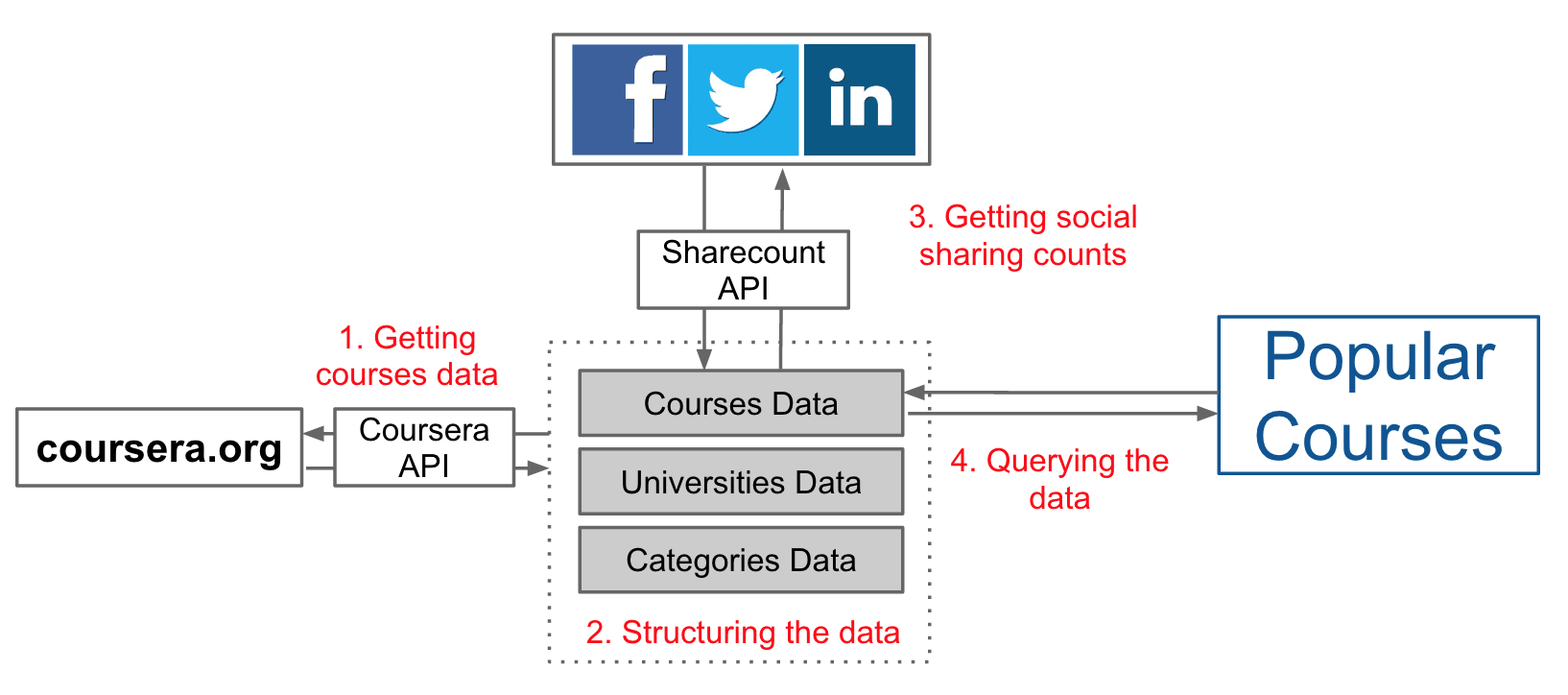
The source code for this tutorial can be found in this github repository.
1. Getting courses data¶
Coursera provides an API for accessing the courses, universities, categories, instructors and sessions data. For this tutorial, we will be using the courses, universities and categories data.
in a Python shell, we start by importing the 3 following libraries: urllib2, json, and pandas. Both urllib2 and json libraries are part of the core python libraries and don't need to be installed separately.
In [1]:
import urllib2
import json
import pandas as pd
Next, we access the coursera API and download the course catalogue. For each course, we are interested in 3 fields:
shortName: The short name associated with the course.name: The course name or title.language: The language code for the course. (e.g. 'en' means English.)
We also include in the query universities and categories parameters. This will return the ids that matches each course with their corresponding universities and categories. Below are the Python commands to do so.
In [2]:
courses_response = urllib2.urlopen('https://api.coursera.org/api/catalog.v1/courses?fields=shortName,name,language&includes=universities,categories')
courses_data = json.load(courses_response)
courses_data = courses_data['elements']
If we want to get the data about the first course in the courses_data dictionary, we simply execute the command below.
In [3]:
courses_data[0]
Out[3]:
{u'id': 2163,
u'language': u'en',
u'links': {u'categories': [8, 10, 19, 20], u'universities': [65]},
u'name': u'The Land Ethic Reclaimed: Perceptive Hunting, Aldo Leopold, and Conservation',
u'shortName': u'perceptivehunting'}
The first course in the courses_data dictionary is 'The Land Ethic Reclaimed: Perceptive Hunting, Aldo Leopold, and Conservation', offered in English by the university with id=65, and under categories 8, 10, 19 and 20.
Next, we retrieve the universities and categories data from the Coursera API. For the universities data, we are interested in the university name and its location.
In [4]:
universities_response = urllib2.urlopen('https://api.coursera.org/api/catalog.v1/universities?fields=name,locationCountry')
universities_data = json.load(universities_response)
universities_data = universities_data['elements']
We can get the data about the first university from universities_data by executing the following command:
In [5]:
universities_data[0]
Out[5]:
{u'id': 234,
u'links': {},
u'locationCountry': u'CN',
u'name': u"Xi'an Jiaotong University",
u'shortName': u'xjtu'}
Similarly, we can get the courses categories data by executing the following commands.
In [6]:
categories_response = urllib2.urlopen('https://api.coursera.org/api/catalog.v1/categories')
categories_data = json.load(categories_response)
categories_data = categories_data['elements']
We can get the data about the the first category from categories_data by executing the following command:
In [7]:
categories_data[0]
Out[7]:
{u'id': 5, u'links': {}, u'name': u'Mathematics', u'shortName': u'math'}
2. Structuring the data¶
In this section, we will structure the courses_data, universities_data and categories_data into pandas DataFrames, and we will map the universities and categories ids with the corresponding names. By the end of this section, we will have one pandas DataFrame called courses_df that will have all the necessary data in a well structured format.
2.1. Putting the data into Pandas DataFrames¶
First, we start by creating a pandas DataFrame for the courses data.
In [8]:
courses_df = pd.DataFrame()
Next, we add the course_name, course_language, course_short_name, categories and universities columns to the courses_df DataFrame.
In [9]:
courses_df['course_name'] = map(lambda course_data: course_data['name'], courses_data)
courses_df['course_language'] = map(lambda course_data: course_data['language'], courses_data)
courses_df['course_short_name'] = map(lambda course_data: course_data['shortName'], courses_data)
courses_df['categories'] = map(lambda course_data: course_data['links']['categories'] if 'categories' in course_data['links'] else [], courses_data)
courses_df['universities'] = map(lambda course_data: course_data['links']['universities'] if 'universities' in course_data['links'] else [], courses_data)
We can print the first 5 rows from the courses_df DataFrame by executing the command below.
In [10]:
courses_df.head()
Out[10]:
| course_name | course_language | course_short_name | categories | universities | |
|---|---|---|---|---|---|
| 0 | The Land Ethic Reclaimed: Perceptive Hunting, ... | en | perceptivehunting | [8, 10, 19, 20] | [65] |
| 1 | Contraception: Choices, Culture and Consequences | en | contraception | [3, 8] | [10] |
| 2 | Introduction to Computational Arts: Processing | en | compartsprocessing | [1, 4, 18, 22] | [117] |
| 3 | Introduction to Programming with MATLAB | en | matlab | [12, 15] | [37] |
| 4 | Experimentation for Improvement | en | experiments | [4, 5, 15, 16] | [148] |
Similarly, we create a python DataFrame for the universities data, and we add the university_id, university_name and university_location_country columns to it.
In [11]:
universities_df = pd.DataFrame()
universities_df['university_id'] = map(lambda university_data: university_data['id'], universities_data)
universities_df['university_name'] = map(lambda university_data: university_data['name'], universities_data)
universities_df['university_location_country'] = map(lambda university_data: university_data['locationCountry'], universities_data)
Next, we change the universities_df index to university_id.
In [12]:
universities_df = universities_df.set_index('university_id')
We can print the first 5 rows from the universities_df DataFrame by executing the command below.
In [13]:
universities_df.head()
Out[13]:
| university_name | university_location_country | |
|---|---|---|
| university_id | ||
| 234 | Xi'an Jiaotong University | CN |
| 120 | University of New Mexico | US |
| 10 | University of California, San Francisco | US |
| 56 | University of California, Santa Cruz | US |
| 24 | Hebrew University of Jerusalem |
Next, we create a python DataFrame for the categories data, and we add the category_id and category_name columns to it.
In [14]:
categories_df = pd.DataFrame()
categories_df['category_id'] = map(lambda category_data: category_data['id'], categories_data)
categories_df['category_name'] = map(lambda category_data: category_data['name'], categories_data)
Similarly, we change the categories_df index to category_id.
In [15]:
categories_df = categories_df.set_index('category_id')
We can print the first 5 rows from the categories_df DataFrame by executing the command below.
In [16]:
categories_df.head()
Out[16]:
| category_name | |
|---|---|
| category_id | |
| 5 | Mathematics |
| 10 | Biology & Life Sciences |
| 24 | Chemistry |
| 25 | Energy & Earth Sciences |
| 14 | Education |
2.2. Mapping ids with the corresponding names¶
In the courses_df DataFrame, the universities and the categories are referred to by their ids and not by their name. To change that, we start by defining a function that change the ids to their corresponding names.
In [17]:
def map_ids_names(ids_array, df, object_name):
names_array = []
for object_id in ids_array:
try:
names_array.append(df.loc[object_id][object_name])
except:
continue
return names_array
For example, we can print the categories with ids [4,5,15,16] by executing the command below.
In [18]:
map_ids_names([4,5,15,16], categories_df, 'category_name')
Out[18]:
[u'Information, Tech & Design', u'Mathematics', u'Engineering', u'Statistics and Data Analysis']
Similarly, we can print the name of the university with id 234 by executing the command below.
In [19]:
map_ids_names([234], universities_df, 'university_name')
Out[19]:
[u"Xi'an Jiaotong University"]
Next, we add both the categories and universities name to the courses_df DataFrame.
In [20]:
courses_df['categories_name'] = courses_df.apply(lambda row: map_ids_names(row['categories'], categories_df, 'category_name'), axis=1)
courses_df['universities_name'] = courses_df.apply(lambda row: map_ids_names(row['universities'], universities_df, 'university_name'), axis=1)
2.3. Adding course URLs to the data¶
The URL to each Coursera course looks like https://www.coursera.org/course/<shortName>. We can add the URLs to the courses_df DataFrame by executing the command below.
In [21]:
courses_df['course_url'] = 'https://www.coursera.org/course/' + courses_df['course_short_name']
We can print the first 5 rows from the courses_df DataFrame by executing the command below.
In [22]:
courses_df.head()
Out[22]:
| course_name | course_language | course_short_name | categories | universities | categories_name | universities_name | course_url | |
|---|---|---|---|---|---|---|---|---|
| 0 | The Land Ethic Reclaimed: Perceptive Hunting, ... | en | perceptivehunting | [8, 10, 19, 20] | [65] | [Health & Society, Biology & Life Sciences, Fo... | [University of Wisconsin–Madison] | https://www.coursera.org/course/perceptivehunting |
| 1 | Contraception: Choices, Culture and Consequences | en | contraception | [3, 8] | [10] | [Medicine, Health & Society] | [University of California, San Francisco] | https://www.coursera.org/course/contraception |
| 2 | Introduction to Computational Arts: Processing | en | compartsprocessing | [1, 4, 18, 22] | [117] | [Computer Science: Theory, Information, Tech &... | [State University of New York] | https://www.coursera.org/course/compartsproces... |
| 3 | Introduction to Programming with MATLAB | en | matlab | [12, 15] | [37] | [Computer Science: Software Engineering, Engin... | [Vanderbilt University] | https://www.coursera.org/course/matlab |
| 4 | Experimentation for Improvement | en | experiments | [4, 5, 15, 16] | [148] | [Information, Tech & Design, Mathematics, Engi... | [McMaster University] | https://www.coursera.org/course/experiments |
3. Getting social sharing counts¶
3.1. Getting social counts from sharedcount.com¶
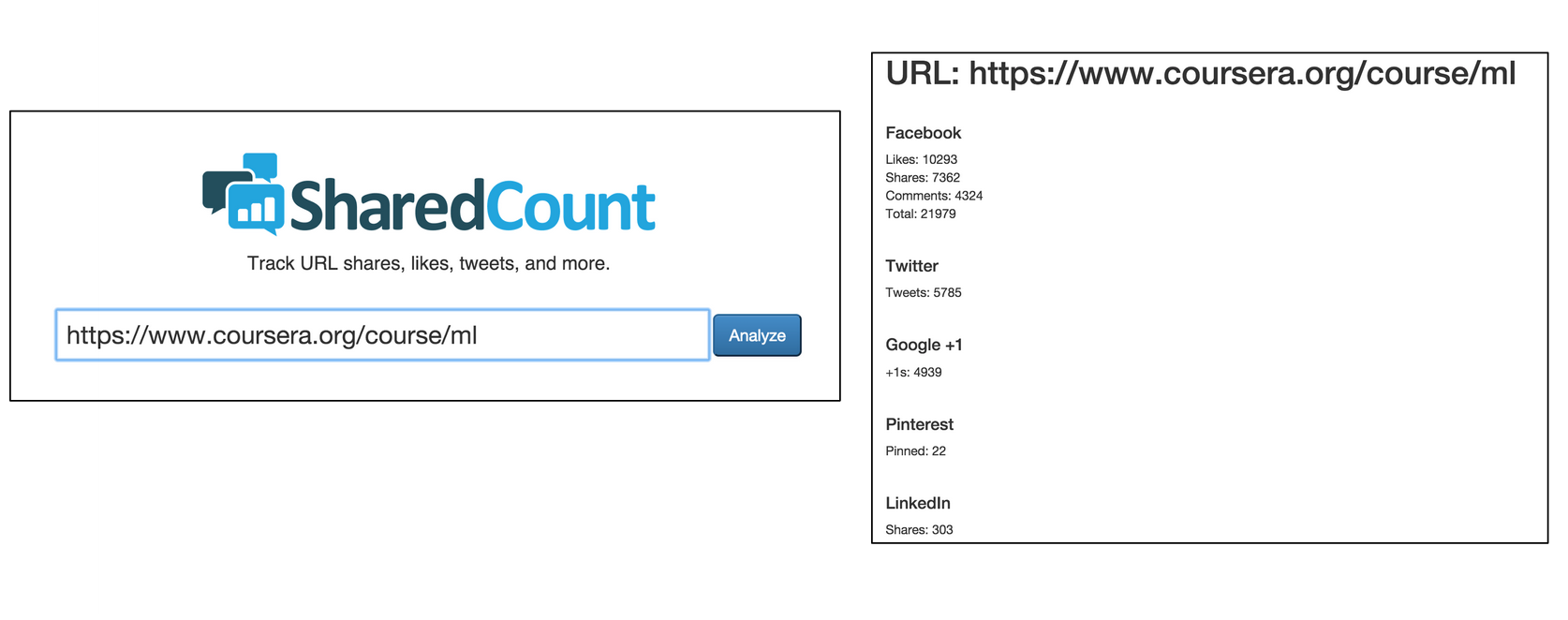
SharedCount is a service that looks up the number of times a given URL has been shared on major social networks. We can get the social shares number of any web page by going to sharedcount.com, entering the page URL in the input field and pressing the "Analyze" button. Below is the output of the very popular Machine Learning course from Stanford that has the URL https://www.coursera.org/course/ml.
3.2. Getting social counts using the sharedcount.com API¶
In our dataset, we want to get the social share of more than 1000 courses. Looking up each course URL from the browser is not efficient. Fortunately, sharedcount.com provides an API that we can use for automating this process. In order to use the API, you should create an account and get your API key. The API allows a daily quota of 10,000 requests which more than enough for this use case. We start by defining a function that returns the social shares from sharecount.com
In [23]:
def get_social_metrics(url, api_key):
sharedcount_response = urllib2.urlopen('https://free.sharedcount.com/?url=' + url + '&apikey=' + api_key)
return json.load(sharedcount_response)
Next we define a variable that holds the API key. Make sure to enter your API key.
In [24]:
SHAREDCOUNT_API_KEY = 'XXXXXXXXXXXXXXXX'
In [25]:
courses_df['sharedcount_metrics'] = map(lambda course_url: get_social_metrics(course_url, SHAREDCOUNT_API_KEY), courses_df['course_url'])
In this tutorial, we will be only using the social share count from Twitter, LinkedIn and Facebook, We can add this information to the courses_df DataFrame by executing the commands below.
In [26]:
courses_df['twitter_count'] = map(lambda sharedcount: sharedcount['Twitter'], courses_df['sharedcount_metrics'])
courses_df['linkedin_count'] = map(lambda sharedcount: sharedcount['LinkedIn'], courses_df['sharedcount_metrics'])
courses_df['facebook_count'] = map(lambda sharedcount: sharedcount['Facebook']['total_count'], courses_df['sharedcount_metrics'])
We can print the first 5 rows from the courses_df DataFrame by executing the command below.
In [27]:
courses_df.head()
Out[27]:
| course_name | course_language | course_short_name | categories | universities | categories_name | universities_name | course_url | sharedcount_metrics | twitter_count | linkedin_count | facebook_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | The Land Ethic Reclaimed: Perceptive Hunting, ... | en | perceptivehunting | [8, 10, 19, 20] | [65] | [Health & Society, Biology & Life Sciences, Fo... | [University of Wisconsin–Madison] | https://www.coursera.org/course/perceptivehunting | {u'StumbleUpon': 0, u'Reddit': 0, u'Delicious'... | 92 | 1 | 1032 |
| 1 | Contraception: Choices, Culture and Consequences | en | contraception | [3, 8] | [10] | [Medicine, Health & Society] | [University of California, San Francisco] | https://www.coursera.org/course/contraception | {u'StumbleUpon': 0, u'Reddit': 0, u'Delicious'... | 199 | 3 | 1704 |
| 2 | Introduction to Computational Arts: Processing | en | compartsprocessing | [1, 4, 18, 22] | [117] | [Computer Science: Theory, Information, Tech &... | [State University of New York] | https://www.coursera.org/course/compartsproces... | {u'StumbleUpon': 0, u'Reddit': 0, u'Delicious'... | 168 | 1 | 1009 |
| 3 | Introduction to Programming with MATLAB | en | matlab | [12, 15] | [37] | [Computer Science: Software Engineering, Engin... | [Vanderbilt University] | https://www.coursera.org/course/matlab | {u'StumbleUpon': 0, u'Reddit': 0, u'Delicious'... | 1 | 0 | 12 |
| 4 | Experimentation for Improvement | en | experiments | [4, 5, 15, 16] | [148] | [Information, Tech & Design, Mathematics, Engi... | [McMaster University] | https://www.coursera.org/course/experiments | {u'StumbleUpon': 0, u'Reddit': 0, u'Delicious'... | 48 | 122 | 314 |
In [28]:
cols_to_show = ['course_name', 'universities_name', 'categories_name', 'twitter_count', 'linkedin_count', 'facebook_count']
#Get English courses
query = courses_df[courses_df['course_language'] == 'en']
#Sort the courses by twitter count and get the top 10 courses
query = query.sort('twitter_count', ascending=0).head(10)
query[cols_to_show]
Out[28]:
| course_name | universities_name | categories_name | twitter_count | linkedin_count | facebook_count | |
|---|---|---|---|---|---|---|
| 428 | Gamification | [University of Pennsylvania] | [Information, Tech & Design, Business & Manage... | 10302 | 8358 | 23322 |
| 209 | Functional Programming Principles in Scala | [École Polytechnique Fédérale de Lausanne] | [Computer Science: Software Engineering] | 6712 | 699 | 9922 |
| 389 | Machine Learning | [Stanford University] | [Statistics and Data Analysis, Computer Scienc... | 5792 | 306 | 21879 |
| 321 | Cryptography I | [Stanford University] | [Computer Science: Theory, Computer Science: S... | 4367 | 8358 | 15066 |
| 258 | Social Network Analysis | [University of Michigan] | [Information, Tech & Design, Computer Science:... | 3895 | 39 | 10315 |
| 857 | Principles of Reactive Programming | [École Polytechnique Fédérale de Lausanne] | [Computer Science: Software Engineering] | 3216 | 8358 | 2739 |
| 761 | Think Again: How to Reason and Argue | [Duke University] | [Humanities , Teacher Professional Development] | 2950 | 160 | 0 |
| 685 | Model Thinking | [University of Michigan] | [Economics & Finance, Humanities ] | 2721 | 370 | 10485 |
| 23 | An Introduction to Interactive Programming in ... | [Rice University] | [Computer Science: Software Engineering] | 2630 | 8358 | 430 |
| 33 | E-learning and Digital Cultures | [The University of Edinburgh] | [Education] | 2629 | 8358 | 5186 |
4.1. Getting the top 10 most popular English courses in "Statistics and Data Analysis" by Twitter count¶
In [29]:
#Get English courses
query = courses_df[courses_df['course_language'] == 'en']
#Filter the "Statistics and Data Analysis" courses
query = query[query['categories_name'].map(lambda categories_name: 'Statistics and Data Analysis' in categories_name)]
#Sort the courses by twitter count and get the top 10 courses
query = query.sort('twitter_count', ascending=0).head(10)
query[cols_to_show]
Out[29]:
| course_name | universities_name | categories_name | twitter_count | linkedin_count | facebook_count | |
|---|---|---|---|---|---|---|
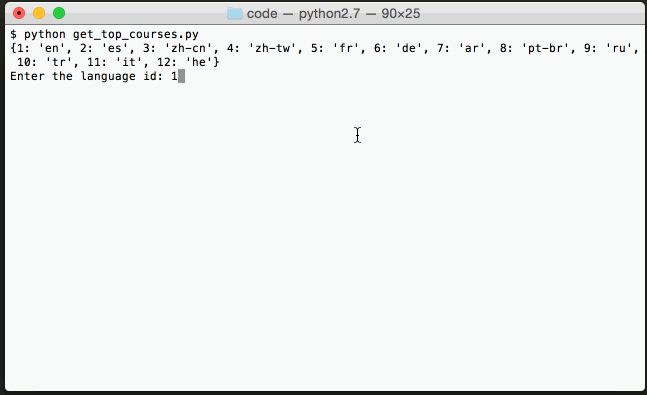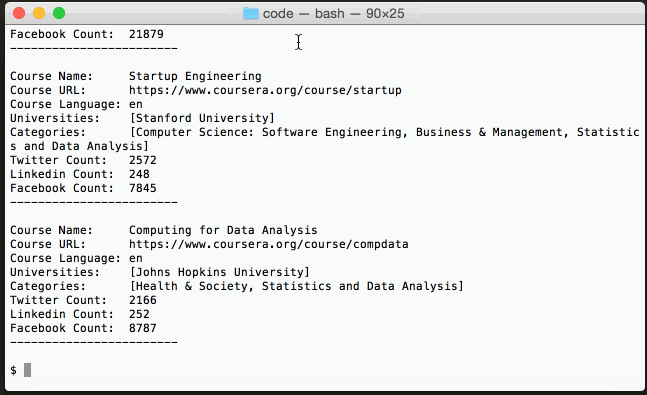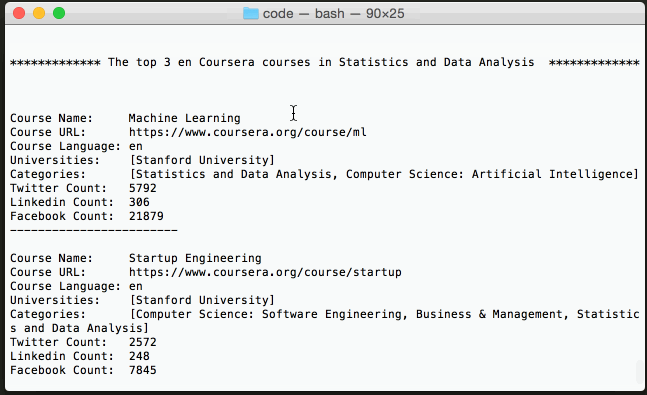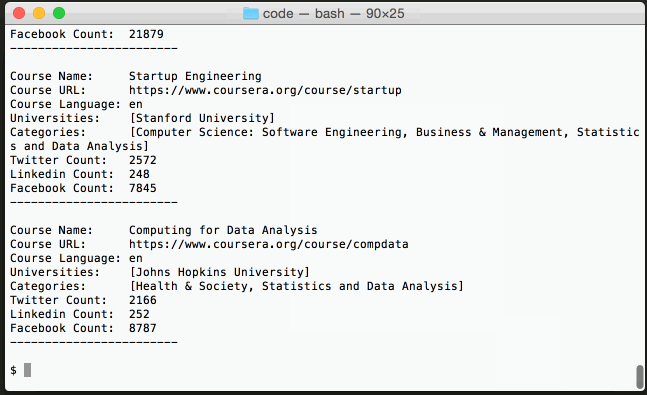
| 389 | Machine Learning | [Stanford University] | [Statistics and Data Analysis, Computer Scienc... | 5792 | 306 | 21879 |
| 791 | Startup Engineering | [Stanford University] | [Computer Science: Software Engineering, Busin... | 2572 | 248 | 7845 |
| 622 | Computing for Data Analysis | [Johns Hopkins University] | [Health & Society, Statistics and Data Analysis] | 2166 | 252 | 8787 |
| 168 | Introduction to Data Science | [University of Washington] | [Information, Tech & Design, Computer Science:... | 1586 | 480 | 4593 |
| 96 | Statistics One | [Princeton University] | [Statistics and Data Analysis] | 1496 | 8358 | 7305 |
| 187 | Data Analysis | [Johns Hopkins University] | [Health & Society, Statistics and Data Analysis] | 1485 | 145 | 4891 |
| 753 | Maps and the Geospatial Revolution | [The Pennsylvania State University] | [Information, Tech & Design, Statistics and Da... | 1363 | 250 | 6754 |
| 492 | Creativity, Innovation, and Change | 创意,创新, 与 变革 | [The Pennsylvania State University] | [Computer Science: Theory, Economics & Finance... | 1226 | 300 | 9518 |
| 106 | The Data Scientist’s Toolbox | [Johns Hopkins University] | [Statistics and Data Analysis] | 815 | 388 | 3936 |
| 886 | R Programming | [Johns Hopkins University] | [Information, Tech & Design, Statistics and Da... | 757 | 8358 | 7031 |
Conclusion¶
In this tutorial, we learned how to use the Coursera API to get the courses catalogue and how to use the sharedcount.com API to get social shares metrics for each course. The technique introduced in this tutorial can be leveraged to other use cases that requires a popularity ranking system for measuring the relevance of a list of links.
The source code for this tutorial can be found in this github repository.
comments powered by Disqus